Log file analysis is underrated.
As the Senior Technical SEO Executive at Custard, I believe learning how to utilise log files should be a part of every SEO’s routine website health checks.
When I was first learning how to carry out log file analysis, I struggled to understand where to begin. Every other blog was telling me how to set up the software and import the files, but not what to look for and why it’s important.
How do you decide what to look for and what actions to take? What will make the most impact?
This article is written as though you’ve already imported some log files into your tool of choice (in my case – Screaming Frog Log File Analyser). You’ve got your data, and you need to know what to do with it.
Things we’ll discuss:
- What is log file analysis?
- Why is log file analysis important?
- So, what shouldn’t be crawled?
- Also important to note…
- Interesting issues I’ve encountered
What is log file analysis?
Log file analysis enables you to observe the precise interactions between your website and Googlebot (as well as other web crawlers such as BingBot). By examining log files, you gain valuable insights that can shape your SEO strategy and address issues related to the crawling and indexing of your web pages.
Why is log file analysis important?
Log file analysis allows you to see exactly what all bots are doing, across all of your content. First-party tools such as Google Search Console or Bing Webmaster Tools provide limited insight into which content is being discovered and crawled by their bots, offering only a tiny fraction of the whole story.
Search engine crawlers such as Googlebot don’t crawl your whole site all in one. Instead, they allow a limited ‘crawl budget’ with crawl sessions being completed until the budget runs out. They’ll come back at a later date to ‘discover’ more new URLs or ‘refresh’ ones they’ve already found.
Since crawl budget is limited, it’s important that search engine spiders spend as little time as possible on URLs that have no organic value. We want spiders to concentrate on the pages that you want indexed, crawled and served to potential customers.
It also means changes to your site such as new product additions or timely blog posts stand a better chance of being picked up and indexed more quickly than those of your competitors.
Keep this in mind when doing the log file analysis. The goal is to make it as easy as possible for bots to access the most important pages on your site. This also helps improve the quality of your SERP placements.
Log file analysis shouldn’t be a one-off task. It’s especially helpful during site migrations and uploading new content to ensure changes are being picked up quickly. Making it a part of a regular SEO strategy will ensure you know exactly which bots are accessing your site, and when.
Cross-checking with a crawler such as Screaming Frog SEO Spider
You could carry out basic log file analysis using only a log file analyser, but to really get the most out of your analysis, you need to add context.
You can use a crawler tool such as Screaming Frog SEO Spider to build a clean list of the URLs you want indexing. Whether these URLs come from the XML Sitemap or a preconceived keyword strategy, feeding them into the project file alongside the log files will help you take a more contextual approach with what you want bots to see.
Importantly, it helps you to see a) which URLs are being crawled that should be crawled; b) which URLs are not being crawled that should be crawled; and c) which URLs are being crawled that definitely should not be crawled.
So, what shouldn’t be crawled?
This really varies from site to site, but to illustrate our point here are a few examples.
Indexable search function and catalogue filters
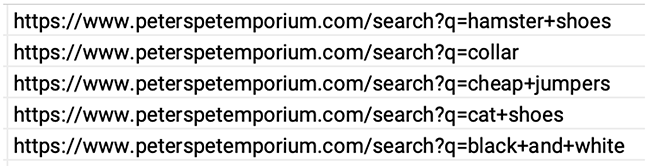
In general, search functions should be blocked in the robots.txt file. There’s rarely any search volume available for the obscure values entered into your site search by end users. There’s also a risk of search results being indexed with undesirable search terms displaying on your pages.
But don’t ignore data through the search box completely – searches should already be tracked through Google Analytics. If you’re finding that there’s a particular search term reoccurring, it could be worth setting up a keyword-targeting landing page and reconfiguring the navigation bar.
Catalogue filter parameters need treating with care. For some variants, there might be sufficient search volume to warrant the creation of a landing page to win that traffic.
For example, at our brand new (and totally not made up) client site ‘Peter’s Pet Emporium’, there’s a variety of ways to filter products matching your criteria. Clicking on each of these modifies the URL – for instance, adding a size and colour selection might add a query string such as: “?colour=red&size=small”.
Here are a few other examples:

If keyword research shows that there is sufficient search volume for ‘denim dog hats’, then you should consider leaving that parameter and value open to crawling and indexing. However, searches for ‘small red dog hats’ might be negligible, meaning it’s not worth having search engine spiders crawling those parameters.
Sites with large inventories should have a solid set of rules in place for which parameters they want to be crawled and indexed, informed by search volume and the quantity of products in stock.
Broken pages
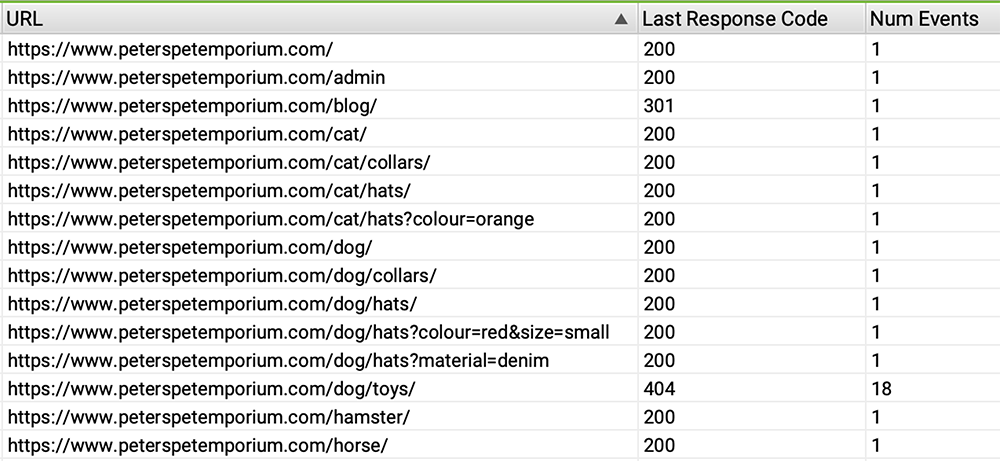
Although you can use a conventional web crawler tool for picking up broken internal links, log file analysis tools can help identify the severity of such issues. URLs which have a large number of 404 crawl ‘events’ can suggest the page that used to live at that address is important. Action should be taken to save not only your crawl budget, but user frustration too.
As well as highlighting which pages need to be fixed first, it sets out a priority list for clients that may have many issues but few resources to fix them.

The URL /dog/toys/ sounds important – we can also see it’s had 18 events! Googlebot likes whatever used to live at this address and routinely spends crawl budget hoping that it comes back. This could be fixed with a 301 redirect to the most appropriate alternative page.
Also important to note…
Log file analysis tools are powerful. To get the most out of them, make sure you take advantage of as many features as possible.
Verifying bots
Make sure to verify bots. Doing this checks the user agents specified by the bots against the IP addresses published by the search engines, ensuring that you don’t waste time on requests that are spoofing Googlebot. This allows you to see exactly what the real Googlebot is doing, and even separate requests coming from either Googlebot Desktop or Googlebot Smartphone.
Within Screaming Frog Log File Analyser this can be done by:
Project > Verify Bots
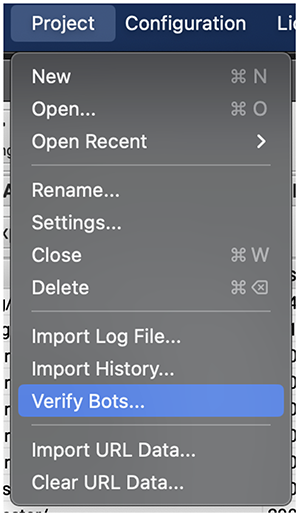
When this has been completed, change ‘Verification Status Show All’ to ‘Verified’.
You can also choose whether you want to see selected Googlebots or those of other search engine crawlers such as BingBot or Yandex.
Configuring bot verification can also reveal if a bot is taking up too many resources, and it could also mean that directives added to your robots.txt only need to be addressed to one specific user-agent.
Utilising Search Console Data
When working through a log file analysis, it’s a good idea to cross check against Google Search Console to see if the page has organic value.
Screaming Frog SEO Spider offers an integration to Google Search Console API to do this in bulk. It can pull in ‘click’ and ‘impression’ data for all discovered URLs, which can then be included in your export to the log file analysis too.
This is a great way of helping to decide whether or not a URL is worth leaving open to being crawled.
Recovering corrupted log file analysis projects
Log files for busy sites can be massive and lead to a huge quantity of data to process in your log file analysis tool. We have clients who receive hundreds of thousands of bot hits per day, and the server access logs for a 14 day period can run into tens of gigabytes in size.
As a result, we’ve experienced issues with Log File Analyser projects becoming corrupted, meaning that when we import fresh logs we lose the ability to compare with past performance.
The only way we’ve found to recover from this is to set up a new project and re-import the historic logs. This means holding on to copies of the original log files.
We have found that backing up to an external hard drive is an efficient means of doing this. It’s inexpensive, it can be encrypted, and is accessible by all of our team.
Interesting issues I’ve encountered
Googlebot 403
After a recent migration to a JS framework site, one of our enterprise level clients reported that Google was not indexing their new site.
It looked perfectly fine to end users, but when checking the log files I discovered that Googlebot was being served a 403 status code. Further investigation helped us to diagnose a misconfiguration within their full page caching setup, meaning Googlebot could not see the page and couldn’t crawl or index the site.
Once the issue had been fed back to the client and addressed, further log file analysis showed that Googlebot could now see the content and was receiving 200 ‘OK’ responses – thereby quickly validating the fix.
Proxy server
On another project, after verifying bots it seemed that the client wasn’t being visited by Googlebot at all despite there being millions of crawls per month reported in Search Console.
I discovered that the client’s website was using a web application firewall. As Googlebot requests passed through the proxy the IP address recorded in the log files was replaced with the ‘internal’ firewall IP instead of Googlebot’s IP address. Requests from the Googlebot user agent were being recorded against IPs which didn’t belong to Google.
This created a complex situation in which there was no telling which bot had visited which URL, and prioritisation became incredibly difficult.
The issue was spotted because I noticed requests to a subdomain on the same server were verified correctly, but requests to the main site weren’t. Googlebot could access the server via another route, which helped to debug the issue.
I worked with the client to get the full list of Google’s IPs whitelisted so bots can pass right through the filter, whilst everybody else is subject to scrutiny.
Overall
It’s always worth a look at client log files if you suspect issues with crawl budget, or to incorporate log file analysis as part of your audits. The log files themselves can be difficult to acquire and store but knowing how to do log file analysis adds an essential dimension to a technical SEO audit.
Log file analysis with Custard
Log file analysis is a complex process, so why not contact the experts? Here at Custard Online Marketing, our technical SEO process involves log file analysis as part of routine health checks on your site.
So, if you’re having difficulties with your site, contact us today. We can have a chat, get to know your brand and your goals, and develop a technical SEO strategy that’s tailor-made to meet your needs.

Jumpstart Your Success